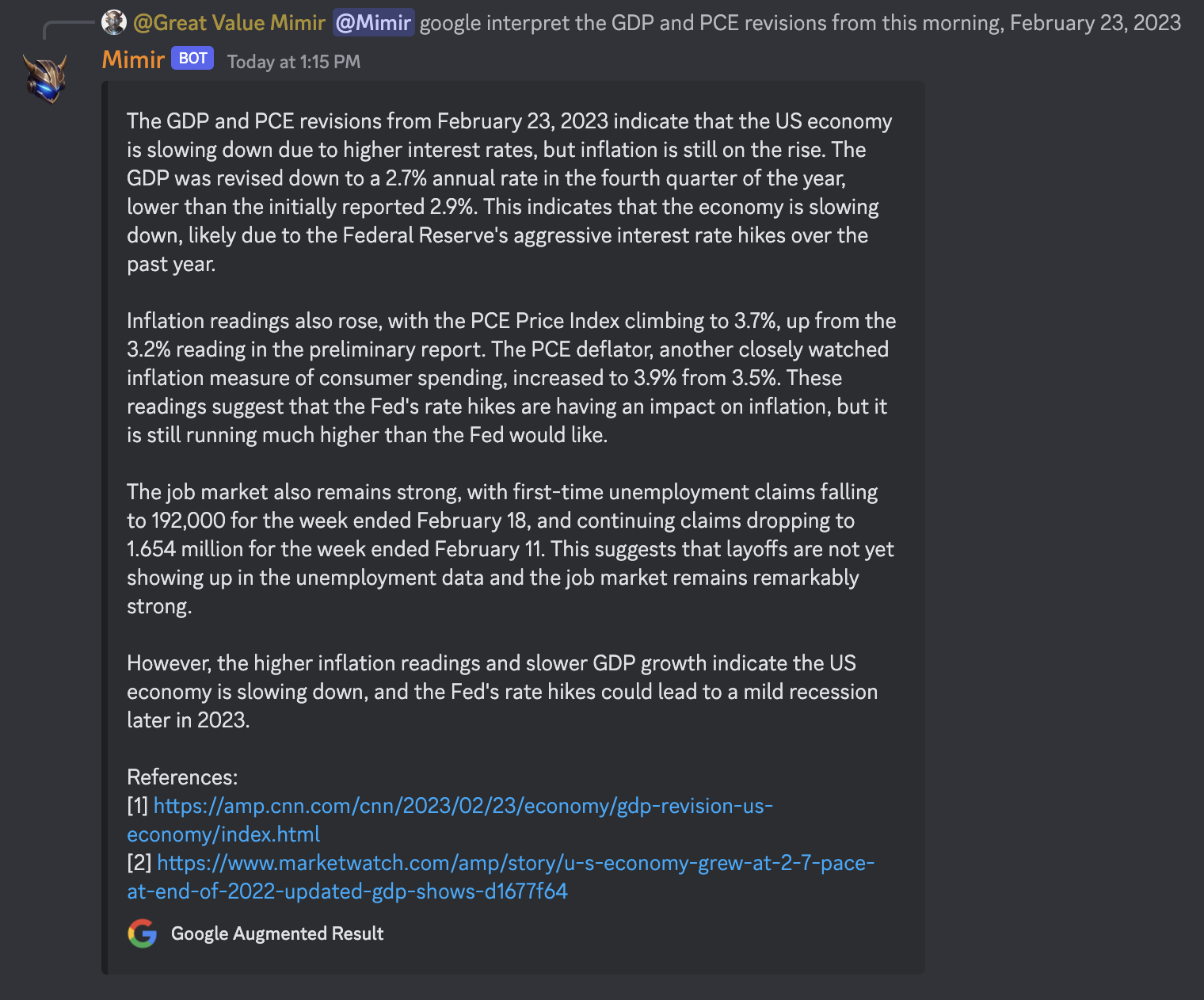
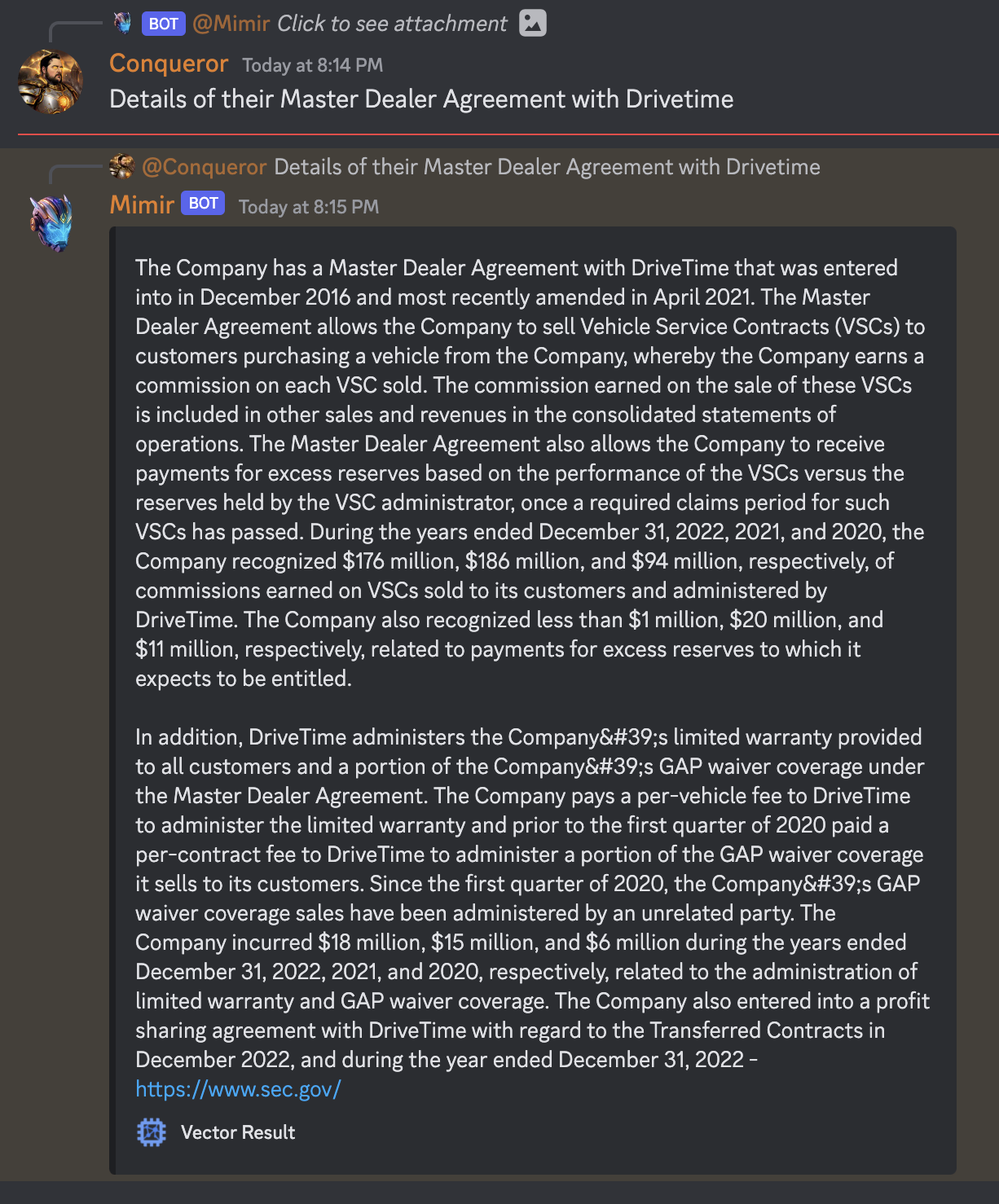
This thread is for discussion and updates related to GPT integrations in Mimir.
For those unaware you can now mention Mimir in Discord and ask it a question and it’ll respond in a fashion similar to the popular “ChatGPT”. Something of note is that the model is trained on data that ends in 2021 so it (despite telling you otherwise quite persistently in some cases) is unaware of anything that has happened since that time. So if you’re asking it general questions like “what gapped up?” or “What is going on with the debt ceiling discussions?” any answer you get will be as though the current time is 2021 (around March or so in most instances).
So again I say FOR FUCKS SAKE THE DATA ENDS IN 2021.
Now that we got that out of the way, we luckily can change this by slipping data to it in the requests. There are currently three types of requests built out:
Market Calendar Data
If you’re asking about the market calendar, you simply have to reference mcal in your question like so:
@Mimir using the mcal data for today, what could’ve caused a drop in the stock market?
This function currently supports referencing today and tomorrow in the query to switch between those specific sets of data. Week data will be implemented soon.
Earnings Calendar Data
Earnings calendar data can be referenced by using ecal.
@Mimir using the ecal data for today and your historical earnings data, what stock is most likely to have the largest move post earnings?
Similarly you can using today, tomorrow and week to switch between time ranges. (this changes the data that Mimir can see)
Candle Data
You can reference this by using candle data in your query and a stock ticker using the cashtag format of $ TICKER (no space same for the example below, just avoiding generating a watchlist entry as I haven’t built a way to avoid that yet.).
@Mimir using the candle data for $ SPY and comparing it to your historical data, would you say that the stock is oversold?
Due to the limited capacity of GPT the candle data is set to 30 hour candles. This limitation is unfortunate but it’s still useful for near term predictions and analysis. I’ve got some ideas on how to increase the capacity but this will be good for now.