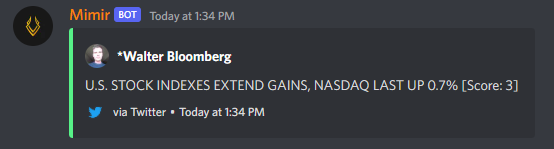
Currently testing a feature that attempts to gauge how algos are “reading” news. This uses a very basic js library called sentiment that I’ll look to replace sooner rather than later, but I wanted to get the concept live for the time being. The embeds for news are colored based upon the sentiment “score”. It’s currently set to color embeds green if a headline/tweet scores > 2 and red if it scores < -2.
And example can be seen below. This thread is for commentary and suggestions on this feature.
This solution has been swapped out with a newer (and far better) GPT based solution. The model understands our current economic picture to some extent and uses that information to judge sentiment on news headlines and tweets. This is currently implemented on Walter Bloomberg & “Breaking Stocks” tweets as well as the new headlines from Benzinga and Dow Jones from Mimir.
Noticed on NFLX’s earnings that it’s not great at deciphering aggregated earnings results but it’s not really geared towards that. I plan on implementing another connector to specific decipher that sort of thing in the future.
If you notice it messing up analysis on something, make note of it here so we can alter its “world view” accordingly.
Mimir actually has a full earnings calendar that updates pretty quickly after releases in the #calendar-earnings channel in Discord but I’m hoping to leverage the headlines that are already rolling and parse the data as it hits since TD is the fastest I know of when it comes to earnings results. So basically when the headlines stream in it should compile data from each headline and when you have EPS & Rev issue an alert if it’s a current position or in a watchlist.
Part of the new sentiment analysis function is a prompt providing input on the current state of the economy. The magic of GPT is that we can “describe the picture” and it does a reasonable job at taking those elements and factoring them into decision making.
It currently works fairly well as a paragraph, however, as we saw with the profiles testing, it does well with JSON data as well.
The current prompt is below (there’s more to it but this is the part that states the picture):
The current macroeconomic environment is high inflation and the FED has been raising interest rates. Inflation has started to come down but there is worry about a wage-price spiral. The stock market wants the FED to lessen the amount of interest rate increases and is hoping for 25 BPS this next round. The stock market is even more hopeful for the FED to announce a pause in interest rate hikes, so any news indicating that may be possible is considered bullish. The current terminal rate estimate is 5% so news indicating that the terminal rate for interest rate increases will be over that is considered bearish.
So, if there are any changes we should make or information that needs added to enhance the picture we’re giving “Mimir”, I’m all ears. Keeping this prompt up-to-date is a pretty high priority as it’ll be used in a lot of Mimir’s decision making in the not-to-distant future.
Secondly: I finally found a key to decode the stupid tagging system the Dow Jones newswires articles use. This will enable us to forward far more targeted stories to TF and make greater use of the data for things like reliably parsing earnings results and analysts adjustments. The list is below.
For those looking to chip in, you can expose the tags of a headline and decode them with the following commands:
Headline Test
!htest <headline>
Lists all the tags and their definitions of a given headline, only need an excerpt of the headline. For example:
Lists recent headlines for the given tag. Alternatively for this function you can use /news mimic ticker which will only show the results to you. For example: